新班子教育政策 Fb網民在談什麼?
【#輿情分析】近日蔡若蓮有機會出任教育局副局長的傳聞鬧得沸沸揚揚,會否影響市民對新班子的教育方面的觀感?
源大數據以大數據反析Facebook上針對新班子教育議題的輿情反應,發現最近7日的負面言論比例一直攀升,而討論焦點亦自7月6日開始轉向蔡若蓮。
相關連結:Facebook帖文
註:本文涉及情感分析僅以系統計算所得,並不反映支持度。
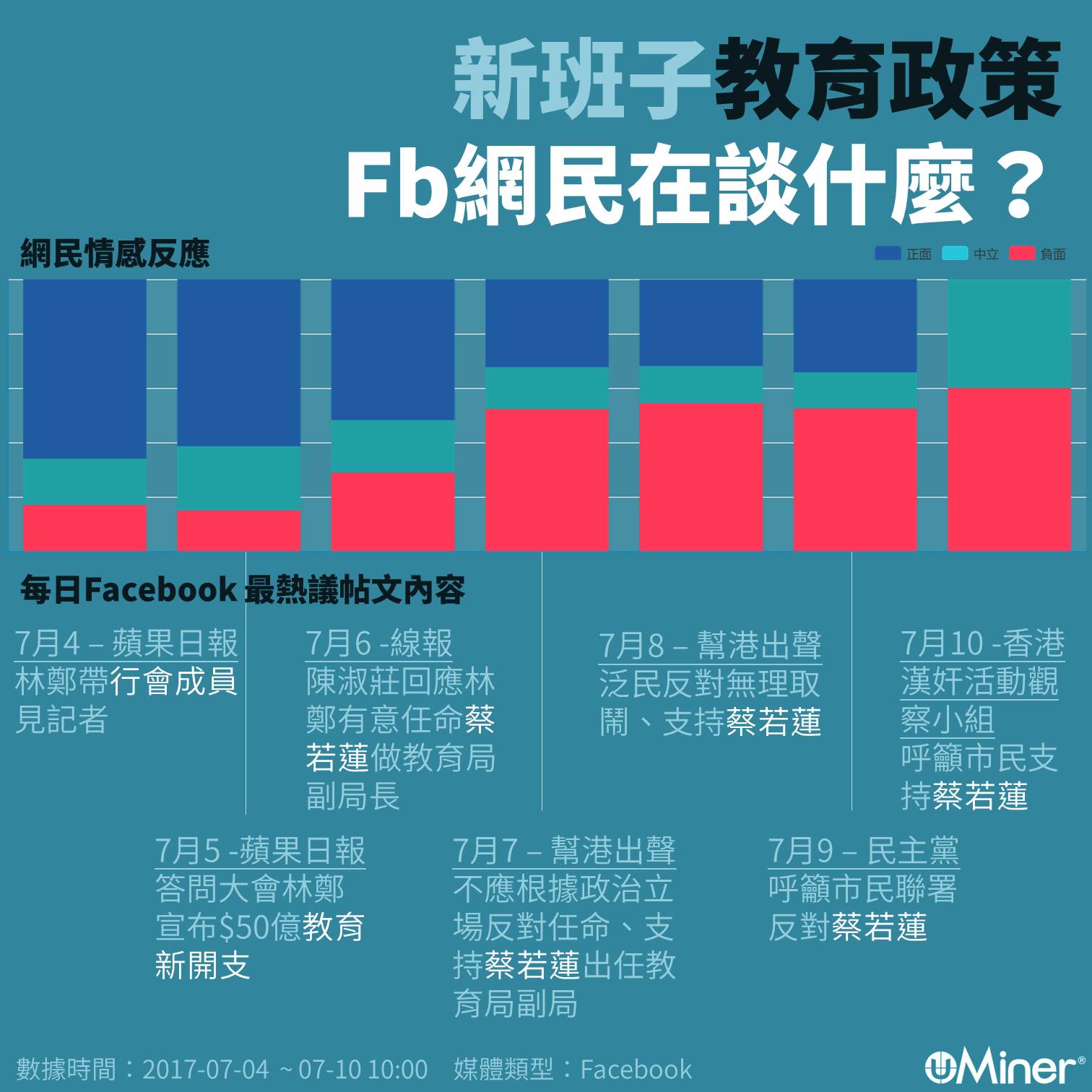
【#輿情分析】近日蔡若蓮有機會出任教育局副局長的傳聞鬧得沸沸揚揚,會否影響市民對新班子的教育方面的觀感?
源大數據以大數據反析Facebook上針對新班子教育議題的輿情反應,發現最近7日的負面言論比例一直攀升,而討論焦點亦自7月6日開始轉向蔡若蓮。
相關連結:Facebook帖文
註:本文涉及情感分析僅以系統計算所得,並不反映支持度。

大數據的價值,可以體現在其可實時記錄、累積、可計算、
數據是否愈多愈好呢?Google.org曾經推出過一
垃圾信息過多 出現偽相關
後來,有學者發現,2013年的GFT預測數據兩倍於C
當前,在文本大數據領域利用關鍵字來進行數據搜集和分析
順便舉個例子。在特首選舉期間,張Sir也跟風與團隊一
還是那一句,大數據不是鬥「大」,數據質量才關鍵。
張榮顯 博士
亞太區互聯網研究聯盟主席、香港源大數據首席顧問
(原文載於經濟日報,獲准轉載)
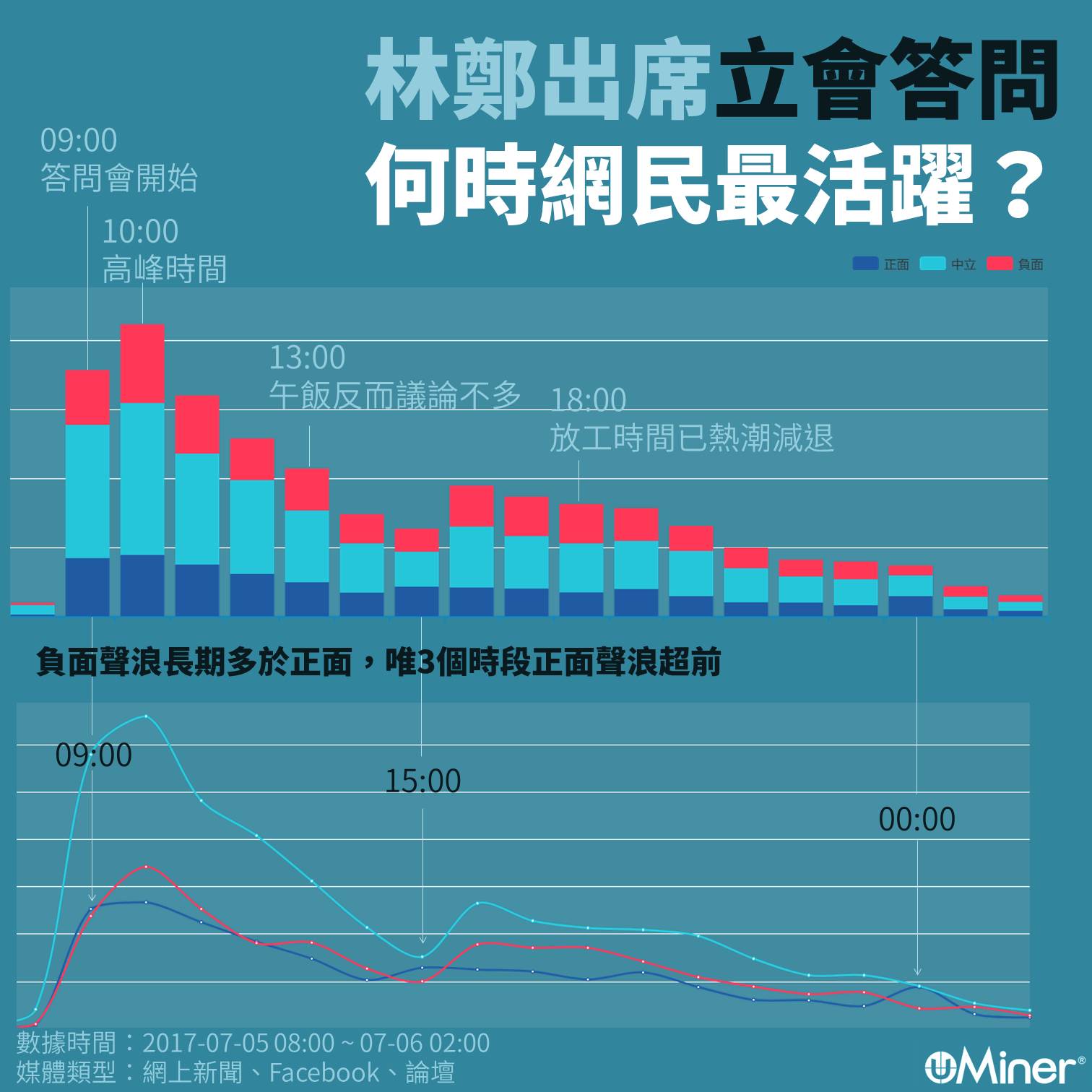
【#輿情分析】常言道:發帖的時機在Lunch/放工,因為網民最活躍。然而源大數據以特首答問會作例,以大數據分析,發現午飯及放工時段網上討論並不特別多。
事件發生時輿論達至高峰,其後一直下滑,直至下午4時突然回升。
而負面聲浪長期高於正面,唯在上午9時、下午3時及午夜12時正面聲浪超前。
相關連結:Facebook帖文
註:本文涉及情感分析僅為系統計算所得,並不反映支持度。☕
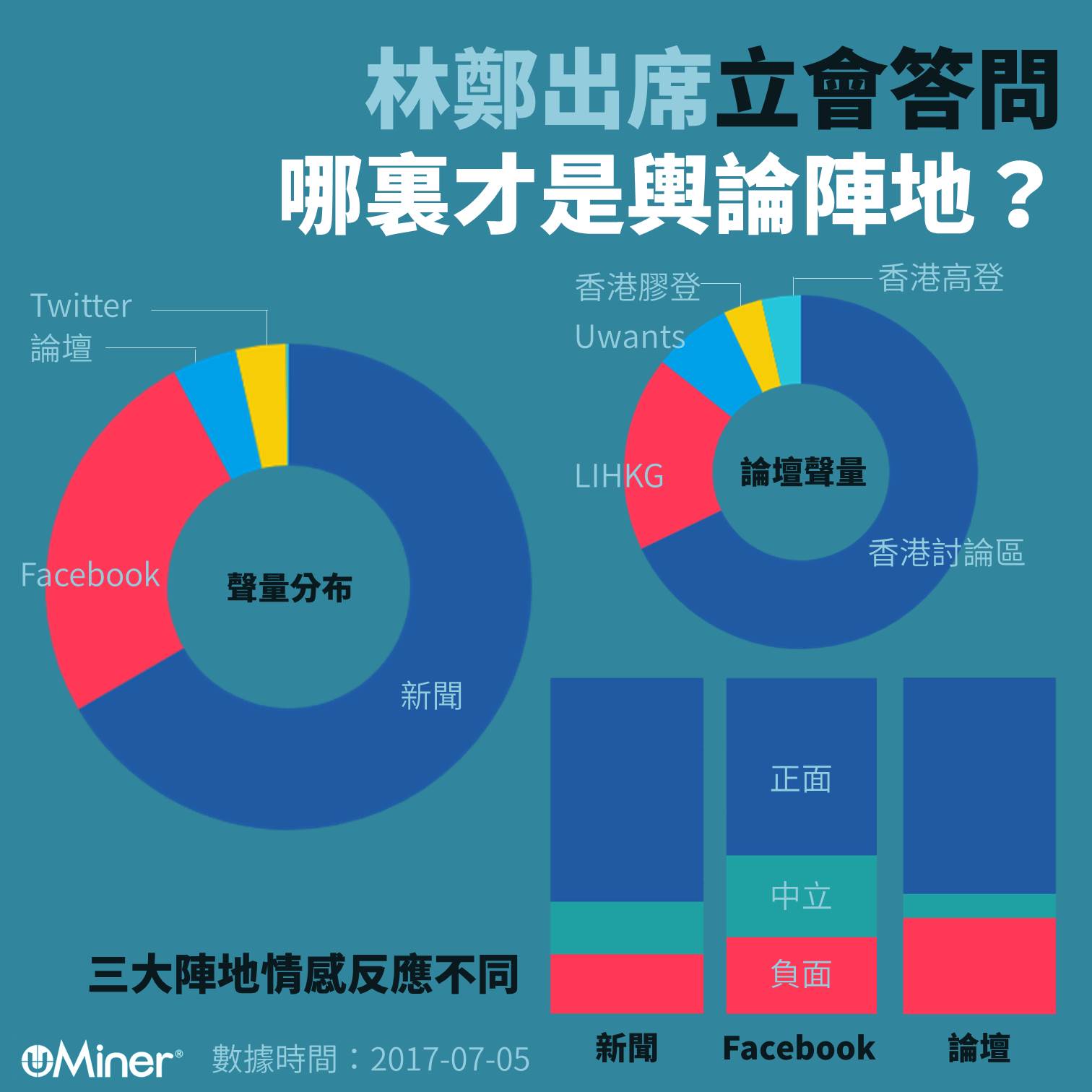
【輿情分析】經過一日沉澱,網路上對特首答問會的情感反應出現變化,與答問會剛開始一小時比較,一日下來正面與中立情感明顯增加。
我們以機器分析昨日數據,發現新聞依然以正面情感佔多,而Facebook的中立及負面情感比例類近,共佔近半,而論壇的中立情感比例屬三大陣地中最少。
就是次答問會的聲量而言,新聞及Facebook合共佔去逾九成,而論壇名列第三,但僅佔約4%。論壇當中,以香港討論區居首,佔七成聲量,大幅拋離第二名香港連登LIHKG。
相關連結:Facebook帖文
註:本文章涉及情感分析僅以系統計算所得,並不反映支持度。
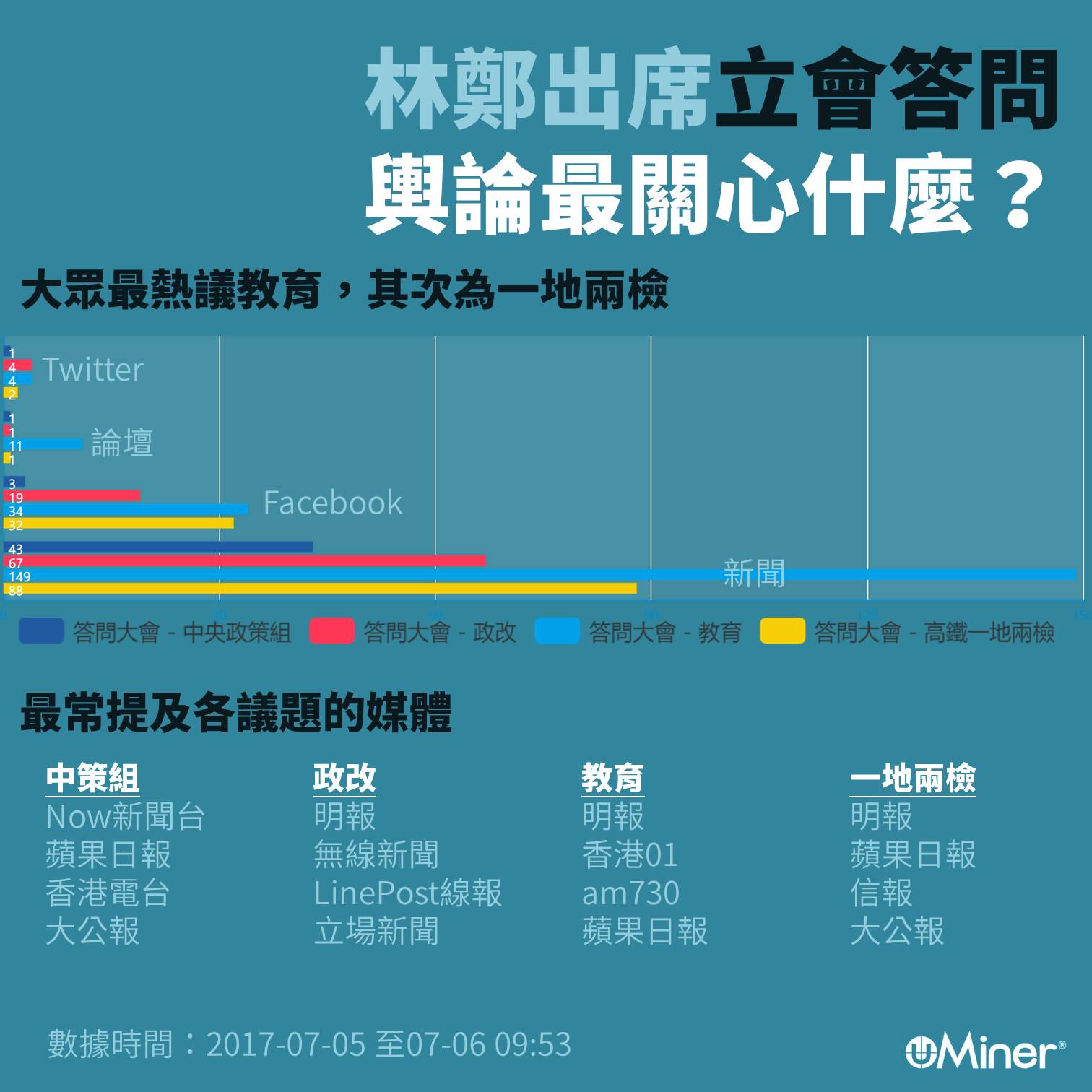
【輿情分析】昨日特首林鄭月娥出席立會答問大會,答問會結束後翌日,源大數據選取較為熱門的四大議題,再以機器分析,看公眾對之的熱議程度。
四大議題在各大輿論陣地的排名相當類近,然而新聞及論壇明顯對教育較感興趣,而在Facebook上,一地兩檢與教育的熱議程度旗鼓相當。
相關連結:Facebook帖文
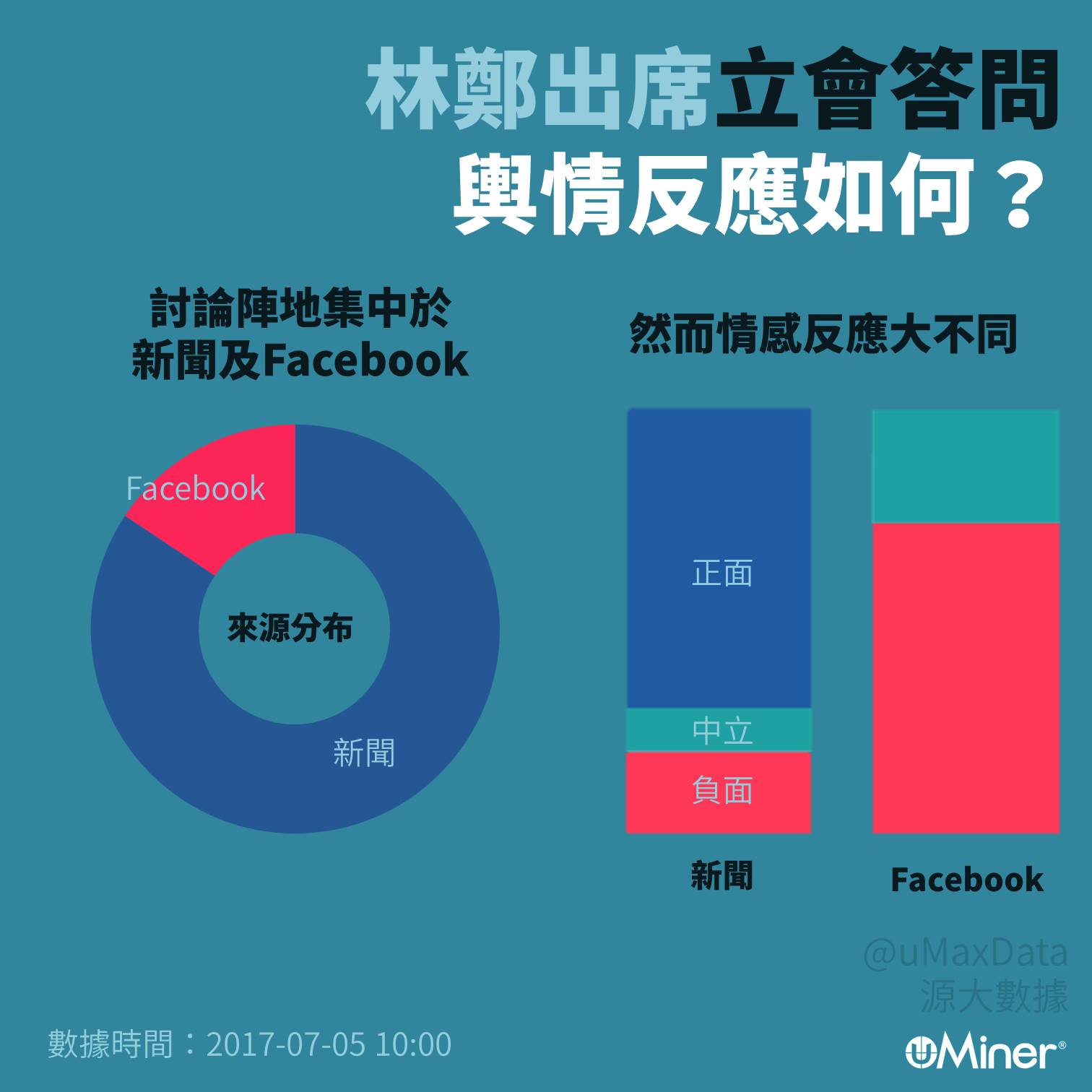
新任行政長官林鄭月娥現正出席立會答問大會, 源大數據即時做輿情分析, 發現新聞與Facebook最快開始討論, 成為主要輿論陣地。然而討論剛開始時, 兩者反應甚為不同, 新聞多措詞正面, Facebook上則以負面措詞為主。
相關連結:Facebook帖文
註:本文涉及情感分析為系統計算所得,並不反映支持度。

「大數據」(Big data)一詞在Google Trend的搜尋榜上,過去幾年一直處於人氣飆升的狀態
上期張Sir簡單講過大數據的四個V(Volume, Variety, Velocity, Veracity),其實也是為了附和目前流行的講法而
張Sir認為,對大數據迷戀也好,抗拒也好,重點要搞清
數字、文字或圖片 分分秒秒累積
我們經常聽到的是某某在講大數據如何做到精準計算消費者
又如打車軟件,從乘客利用APP搜索車輛開始,到司機接
再如,上述的兩個場景中,如加插交易成功後,消費者/乘
從上面三個例子中,我們可以看出,大數據是有身段的,有
張榮顯 博士
亞太區互聯網研究聯盟主席、香港源大數據首席顧問
(原文載於經濟日報,獲准轉載)

Big data is like teenage sex: everyone talks about it, nobody really knows how to do it.
People think big data as the petroleum of the future: you rule if you control it. Yet like petroleum, data has to be carefully extracted and managed, which is the real question.
Besides the traditional saying of 4V: Volume, Variety, Velocity and Veracity, we have to look into the 5th V: Value, which is the even more determining factor of your analytics…

香港江湖電影的情節中,常常出現講數的場面,大佬對大佬
張Sir關注及實踐大數據應用多年,近年頻頻出席研討會
擁有很易 提煉很難
有人說大數據是未來的石油,也有人說大數據是企業的資產
正如教科書式的說法,大數據有四個V,即是量大(vol
舉個簡單的例子,目前商界和政界都流行使用一些社交媒體
張榮顯 博士
亞太區互聯網研究聯盟主席、香港源大數據首席顧問
(原文載於經濟日報,獲准轉載)

Living in the hustle and bustle city, waiting is a sin to efficiency. Yet people spend much of their time waiting in transport, restaurants, clinics, banks, etc.
To improve the living quality, limiting the waiting time is essential. Hong Kong has strong digital infrastructure including network coverage with high speed, which can be a great weapon in developing smart city. Here is how…