
作者:源大數據團隊 ( 張榮顯,趙瑩,曹文鴛 )
在人人都談論大數據和人工智能的時代,社會科學研究的未來是否可以與這些新的技術發展結伴而行?我們如何結合人工智能和社會科學研究,以大數據洞悉民意?

社會科學是探索人類社會及其發展規律的科學,這一領域涉及哲學、經濟學、法學、政治學、社會學、歷史學、文學、藝術等學科。隨著大數據時代的到來,人工智能(Artificial Intelligence)、機器學習(Machine Learning)、深度學習(Deep Learning)等為社會科學研究帶來了新的機遇和視野,但同時也因社會科學領域研究者所掌握的技術、算法的相關知識相對較為薄弱,使得其對人工智能等技術應用望而卻步。
什麼是人工智能?
人工智能主要指機器以模仿人類智能的方式執行任務,[1]具體來說,可從三個層次理解人工智能。
第一個層面比較泛泛而談,指機器執行我們通常理解的(human-like understanding)任務的能力。[2]
第二個層面綜合了類似人類的多種能力,即機器具有像人類一樣感知(sense)、理解(comprehend)、行動(act)、學習(learn)的能力。[3]
第三個層面上升至認知和判斷並解決問題的能力,人工智能顯示出類似人類的認知能力和執行能力,強調人工智能是一種複雜的技術應用,機器能展示人類的認知功能(human cognitive),如學習、分析和解決問題。[4]

總體來講,人工智能主要集中在類似人類的感知、認知和判斷能力方面的探索和實踐。
根據機器是否具有自主意識,可區分為
1 具有自主意識的強人工智能
2不具有自主意識的弱人工智能[5]
弱人工智能主要是模擬人的某些特定的技能,智能處理一些特定場景和應用的問題,實際應用領域包括,例如語音識別,圖像人臉識別,自然語言處理,資料檢索,自動駕駛,智能控制機器人等。
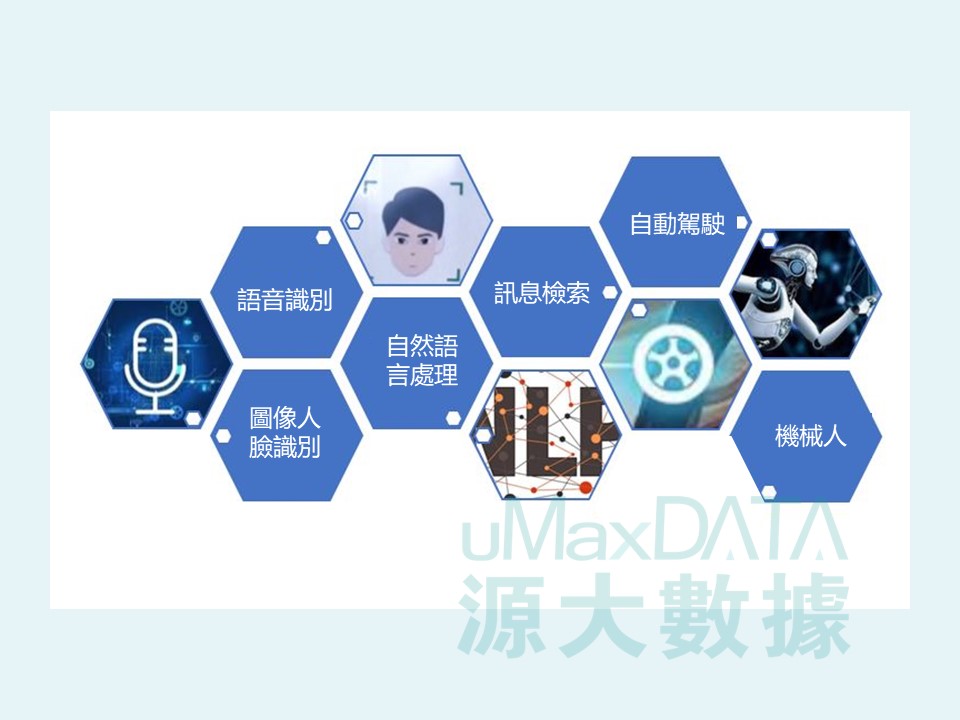
人工智能的發展目前尚停留在弱人工智能階段,正努力向具有自主意識的強人工智能突破。
在社會科學研究中,人工智能多應用在數據的分析和處理過程中,尤其是對文本數據的意義挖掘和價值洞察包括新聞報道、社交網絡的資料、歷史檔案、訪談文字、文獻、政策文檔等。
如何運用人工智從文本中來理解人的行為和想法?
人工智能在文本大數據的挖掘與分析中的應用,集中在媒體監測和趨勢預測等方面。以輿情領域的研究和實踐為例,當前很多應用是處於收集情報的階段,即是人工智能的感知層面。例如,當利用機器獲取數據時,需要考量到數據覆蓋度的問題,具體而言即是數據是否齊全、具代表性、數據質量等,則於人工智能的感知能力相關。
認知,相當於機器通過對自然語言文本的理解,進行智能的自動化歸類和分析,實務上來說,就是如何去測量,從文本中得到意義和洞察結果。
判斷,相當於瞭解了文本之後所作出的決策和行為。也就是說,怎麼解釋、分析、挖掘研究發現,協助用戶可以做出正確的判斷,以為後續採取行動做指引和參考。
這三部曲,就是利用人工智能輔助進行文本數據的挖掘及分析時需要考慮的問題,這也是當前文本大數據挖掘和分析過程中遇到的三大挑戰。詳細說明可參考:
https://mp.weixin.qq.com/s/pnd4UzAQmCudVF0tU6C-fw
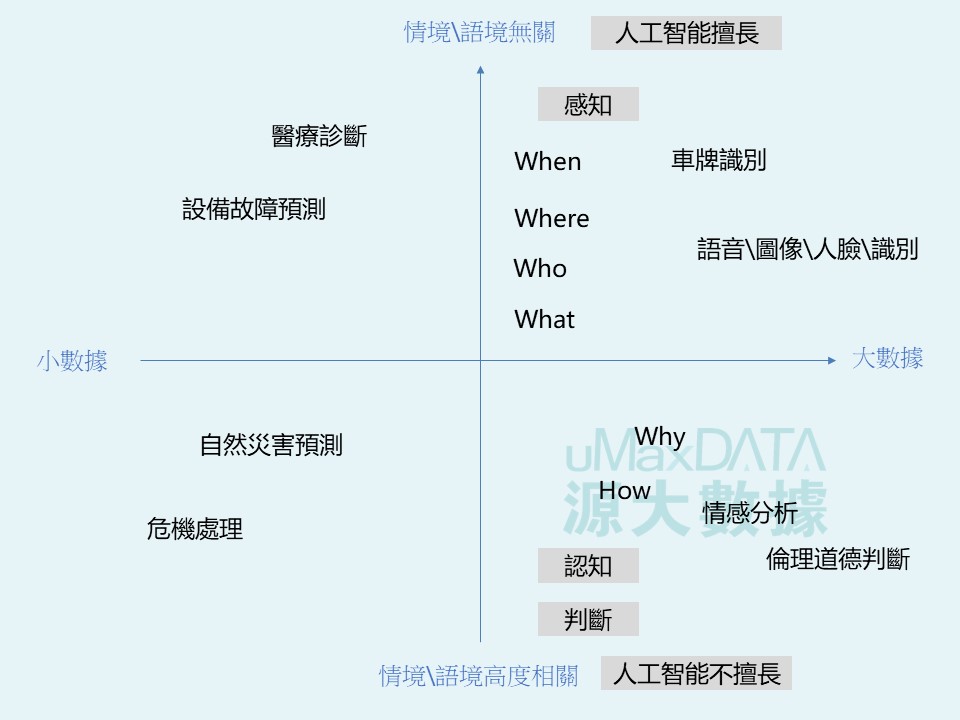
現時人工智能在文本大數據挖掘的方面目前的應用依然較為初步。
以輿情系統為例,當前主要以描述KPI的結果為主(如圖1所示),如數據來源、內容的分類、點贊數、跟帖數、分享量、熱度,情感分析、情緒分析等。這些都是機器感知的一部分,但目前這種分析能力仍然較為表面,如需要找出有助決策的洞察,仍然需要進一步深度的挖掘和分析。
以技術為主導的盲點
現時以技術為主導的分析,往往以程序化、同質化的自動化圖表為主要產出,然而卻限制了我們的想像力,解釋力和判斷力,這樣就限制了我們找出更有洞察力的一些發現。所以從感知、認知到判斷,重要的不是我們所看到的可視化結果,而是這些結果能帶給我們決策和判斷的信心。這就需要從數據庫的建立,到設定分析框架,從測量到分析,應該都是由我們「人」來掌握的,是分析者決定機器給我們看什麼,而不是機器決定我們看什麼。
資訊科技—>社會科學
文本大數據挖掘過程經歷不同的幾個階段。最初,是通過搜索電子簡報,對資料歸類。到現在是輿情監測、品牌聆聽的做法,從符號/信號到歸類資料到資料可視化,目前都已經有很多實踐和應用。現時大部分的輿情分析工具都停留這個階段,不斷鑽研運用機器進行自動化分析的系統或程序。
但想要做到監測之後的分析和挖掘,就需要對文本大數據挖掘有全新的理解,即從資訊科技(Information technology)的視角轉向至社會科學(Social science)的視角,也就是說,資訊科技應該用以輔助社會科學的思路和分析方法。
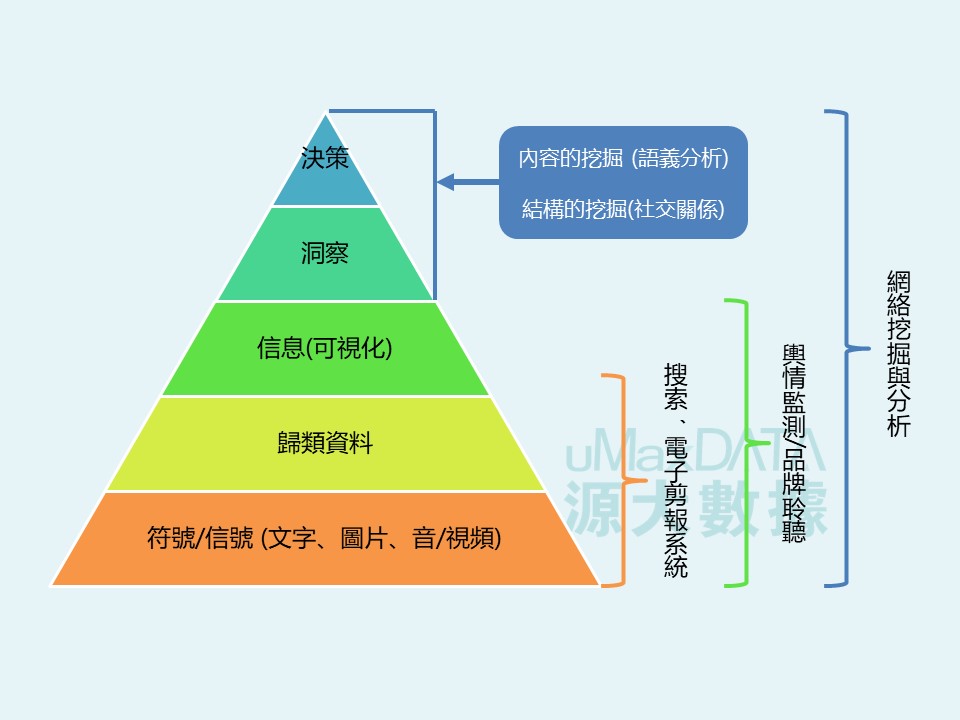
運用人機結合,在內容挖掘、語義分析、結構挖掘和社交關係等分析方面,提升認知和判斷的能力。在充分利用機器輔助的前提下,結合社會科學的概念與方法,以覆蓋度、測量和解釋這三個重要的維度為重心,聚焦人工智能對文本的感知、認知和判斷層面來處理文本大數據所面臨的種種問題。
人工智能+社會科學研究方法
如何實現這種人機結合的機制,將大數據技術與社會科學研究方法結合?源大數據提供的方案,是利用人工智能(AI)結合社會科學研究方法、大數據技術及專業的自然語言處理技術 (NLP),其中包括普通話、粵語及英語,從社交媒體及網絡上搜羅的海量紛亂的網路訊息中提煉出洞察,為客戶提供決策參考。
透過源大數據的方案,可方便分析人員一站式進行研究設計、執行,及結果呈現。源大數據的產品運用一整套科學、系統的大數據技術輔助在線內容分析法,而且設計靈活易用,讓不同背景的用家都可以運用自己的行業智慧和領域專長,找出真正合用的洞察,包括政策研究、企業形象、市場分析、公關危機、產品研究等,都可以運用得宜。
另外,源大的大數據分析平台靈活具彈性,除了具備智能可視化圖表,提煉精準到位的洞察資訊,用戶亦可自行製作圖表以滿足不同研究分析需求。而平台分析結果既可隨時查證結果並逐層追溯至原文,亦可直接下載圖表及更新數據,極具透明度。
延伸閱讀(1)—「推薦系統」能全面了解您的客戶喜好嗎?
https://www.umaxdata.com/hk/news-post-hk.html?_id=1542&category=3
延伸閱讀(2)—公關案例分析2022 :男童挨跌kkplus「天線得得B」事件
https://www.umaxdata.com/hk/news-post-hk.html?_id=1767&category=3
了解源大數據的商業解決方案:
https://www.umaxdata.com/hk/service-hk.html
參考文獻
[1] Marr, B. (2016). What is the difference between artificial intelligence and machine learning? Forbes. Retrieved from:
https://www.forbes.com/sites/bernardmarr/2016/12/06/what-is-the-difference-between-artificial-intelligence-and-machine-learning/#66fdb6862742.
[2] Knowledge@Wharton (2018). Vishal Sikka: Why AI needs a broader, more realistic approach. Retrieved fromhttp://knowledge.wharton.upenn.edu/article/ai-needsbroader- realistic-approach/.
[3] Daugherty, P., Carrel-Billiard, M., & Biltz, M. (2018). Accenture technology vision 2018. Retrieved from. Intelligent Enterprise Unleashed. Accenturehttps://www. accenture.com/t00010101T000000Z__w__/nz-en/_acnmedia/Accenture/next-gen-7/tech-vision-2018/pdf/Accenture-TechVision-2018-Tech-Trends-Report.pdf#zoom=50.
[4] Valin, J. (2018). Humans still needed: An analysis of skills and tools in public relations. Discussion paper. Retrieved from London: Chartered Institute of Public Relations. https://www.cipr.co.uk/sites/default/files/11497_CIPR_AIinPR_A4_v7.pdf.
[5] Searle, J. (1980). Minds, brains and programs. Behavioral and Brain Sciences, 3, 417-457. doi10.1017/S0140525X00005756.